<!-- wp:image {"id":3106,"sizeSlug":"full","linkDestination":"none"} -->

<!-- /wp:image --><!-- wp:uagb/advanced-heading {"block_id":"5d1de109","classMigrate":true,"level":1,"seperatorStyle":"solid","subHeadFontFamily":""} -->
KMO İstatistiği Ne Anlama Geliyor?
İstatistiksel Bilgilendirme
<!-- /wp:uagb/advanced-heading --><!-- wp:paragraph {"dropCap":true} -->
KMO istatistiği açıklayıcı faktör analizinde örneklem yeterliliğini değerlendirmek için kullanılan bir katsayıdır. Bu katsayı, alt boyut belirlemek için açıklayıcı faktör analizinin uygulandığı her çalışmada istisnasız karşımıza çıkmaktadır.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Şimdi bu istatistiği yakından inceleyelim.
<!-- /wp:paragraph --><!-- wp:paragraph -->
KMO istatistiği, Kaiser Meyer Olkin ifadesinin baş harflerinin kısaltmasından geliyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Profesör Ingram Olkin'in de katkısıyla normalize formunda, KMO istatistiği son halini alıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Kaiser (1970) tarafından Psychometrika dergisinde yayınlanmış "A second generation Little Jiffy" isimli makalesi, bu muhteşem istatistiği bilim hayatımıza kazandırmış.
<!-- /wp:paragraph --><!-- wp:paragraph -->
KMO istatistiğinin önerilme sebebi örneklem yeterliliğinin ölçülmesine dayanıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
İşte tam da bu nedenle orjinal çalışmada "Measures of Sampling Adequacy" şeklinde tanımlanmış bir ifade ile karşılaşıyoruz.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Bazı kaynaklarda KMO katsayısı şeklinde de bahsediliyor. Her iki kullanım da bilimsel açıdan uygun.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Bu duruma dikkat çekmek için aşağıdaki başlığı kullanalım.
<!-- /wp:paragraph --><!-- wp:heading -->
KMO Katsayısı (İstatistiği) Nasıl Hesaplanıyor?
<!-- /wp:heading --><!-- wp:paragraph -->
İlk olarak matematiksel hesaplanışına kısaca göz atalım.
<!-- /wp:paragraph --><!-- wp:paragraph -->
KMO istatistiği hesaplanırken iki temel ölçüye ihtiyacımız var:
<!-- /wp:paragraph --><!-- wp:paragraph -->
1.) Değişkenler arası ham korelasyon katsayıları
<!-- /wp:paragraph --><!-- wp:paragraph -->
2.) Değişkenler arası kısmi korelasyon katsayıları
<!-- /wp:paragraph --><!-- wp:paragraph -->
Yukarıda bahsedilen ham ve kısmi korelasyon katsayıları her değişken çifti için ayrı ayrı hesaplanıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
KMO istatistiğinin matematiksel hesaplanışını aşağıdaki formülde gösteriyoruz.
<!-- /wp:paragraph --><!-- wp:image {"id":3110,"width":289,"height":132,"sizeSlug":"full","linkDestination":"none"} -->
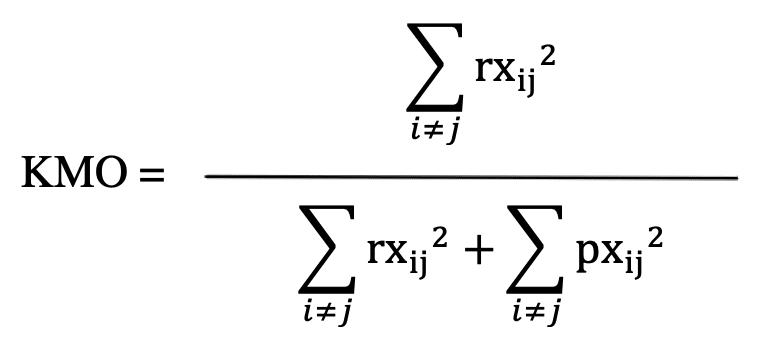
<!-- /wp:image --><!-- wp:paragraph -->
Formülde gösterdiğimiz rxij değişkenler arası korelasyonları; pxij ise değişkenler arası kısmi korelasyonları göstermektedir.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Programların göz açıp kapayıncaya kadar verdiği KMO istatistiğinin arkasında işte bu formülasyon yatıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
KMO istatistiğini hem genel formu ile hem de maddeler için ayrı ayrı hesaplayabiliyoruz.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Anket çalışmalarımızda esasen tıpkı komünalitelerde olduğu gibi ayrı ayrı tüm maddeler için örneklem yeterliliğini bu istatistikle sınayabiliriz.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Bilimsel çalışmalarda bu yoldan ziyade genel KMO istatistiği verilmektedir.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Hesaplanma aşamasında araştırmacıların ıskaladığı, ancak kritik role sahip bir istatistiğimiz var:
<!-- /wp:paragraph --><!-- wp:paragraph -->
Korelasyon katsayısı
<!-- /wp:paragraph --><!-- wp:paragraph -->
Paket programlar bu formülasyon için genelde Pearson korelasyon katsayısını kullanıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Literatürde bazı kaynaklar alternatif korelasyon katsayılarının da kullanılabileceğine işaret etmektedir.
<!-- /wp:paragraph --><!-- wp:image {"id":3109,"sizeSlug":"full","linkDestination":"none"} -->

<!-- /wp:image --><!-- wp:paragraph -->
Özellikle anket çalışmalarında KMO istatistiği karşımıza sıkça çıkıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Çünkü araştırmacılar anketler aracılığı ile ölçek geliştiriyor veya uyarlıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Ölçek geliştirme/uyarlama süreçlerinde alt boyutları belirlemek için de açıklayıcı faktör analizi uyguluyorlar.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Açıklayıcı faktör analizi uygulanırken de yukarıda bahsettiğimiz gibi Pearson korelasyon katsayıları baz alınıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Halbuki anket verilerinde farklı ölçme düzeylerinde değişkenler ile çalışıyoruz ve bu değişken türlerine uygun farklı farklı korelasyon katsayıları geliştirilmiş.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Maalesef bu özel katsayılar literatürde hak ettiği yeri bulmuyor ve klasik Pearson korelasyon ölçüsü baskın geliyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Halbuki bu noktada yapabileceğimiz değişiklikler örneklem yeterliliği başta olmak üzere anket sonuçlarımızda harika değişimler yaratabilme potansiyeline sahip.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Ah şu alışkanlıklar...
<!-- /wp:paragraph --><!-- wp:heading -->
KMO İstatistiği Kaç Olmalı?
<!-- /wp:heading --><!-- wp:paragraph -->
Araştırmalarda çeşitli sınırlar olmakla birlikte, derlenen sonuçlar üzerinden sınırları şu şekilde gösterebiliriz:
<!-- /wp:paragraph --><!-- wp:uagb/icon-list {"block_id":"b6ecf0ae","classMigrate":true,"childMigrate":true,"className":"uagb-icon-list__outer-wrap uagb-icon-list__layout-vertical"} -->
<!-- wp:uagb/icon-list-child {"block_id":"6aa419e0","label":"KMO\u003e0.90 \u003cstrong\u003eMükemmel\u003c/strong\u003e","label_color":"","icon_hover_color":"","label_hover_color":"","icon_bg_hover_color":"","icon_border_hover_color":"","className":"uagb-icon-list-repeater uagb-icon-list__wrapper"} -->
KMO>0.90 Mükemmel
<!-- /wp:uagb/icon-list-child -->
<!-- /wp:uagb/icon-list --><!-- wp:uagb/icon-list {"block_id":"31925370","classMigrate":true,"childMigrate":true,"className":"uagb-icon-list__outer-wrap uagb-icon-list__layout-vertical"} -->
<!-- wp:uagb/icon-list-child {"block_id":"d714848f","label":"0.80\u0026lt;KMO\u0026lt;=0.90 \u003cstrong\u003eÇok iyi\u003c/strong\u003e","label_color":"","icon_hover_color":"","label_hover_color":"","icon_bg_hover_color":"","icon_border_hover_color":"","className":"uagb-icon-list-repeater uagb-icon-list__wrapper"} -->
0.80Çok iyi
<!-- /wp:uagb/icon-list-child -->
<!-- /wp:uagb/icon-list --><!-- wp:uagb/icon-list {"block_id":"fee767e1","classMigrate":true,"childMigrate":true,"className":"uagb-icon-list__outer-wrap uagb-icon-list__layout-vertical"} -->
<!-- wp:uagb/icon-list-child {"block_id":"32eaf033","label":"0.70\u0026lt;KMO\u0026lt;=0.80 \u003cstrong\u003e İyi\u003c/strong\u003e","label_color":"","icon_hover_color":"","label_hover_color":"","icon_bg_hover_color":"","icon_border_hover_color":"","className":"uagb-icon-list-repeater uagb-icon-list__wrapper"} -->
0.70 İyi
<!-- /wp:uagb/icon-list-child -->
<!-- /wp:uagb/icon-list --><!-- wp:uagb/icon-list {"block_id":"fdb5be4a","classMigrate":true,"childMigrate":true,"className":"uagb-icon-list__outer-wrap uagb-icon-list__layout-vertical"} -->
<!-- wp:uagb/icon-list-child {"block_id":"5e67585c","label":"0.60\u0026lt;KMO\u0026lt;=0.70 \u003cstrong\u003e Orta\u003c/strong\u003e","label_color":"","icon_hover_color":"","label_hover_color":"","icon_bg_hover_color":"","icon_border_hover_color":"","className":"uagb-icon-list-repeater uagb-icon-list__wrapper"} -->
0.60 Orta
<!-- /wp:uagb/icon-list-child -->
<!-- /wp:uagb/icon-list --><!-- wp:paragraph -->
0.60'ın altında bir değer örneklem yeterliliğinin kötü olduğunun göstergesidir. Çalışmalar da zaten 0.60'ın altında bir değeri "miserable", yani acınası, berbat olarak tanımlıyor!
<!-- /wp:paragraph --><!-- wp:paragraph -->
Yapılan benzetim (simülasyon) çalışmalarında, çok düşük korelasyonlu verilerde dahi 0.50-0.60 arasında değerlerin elde edildiği görülmüş.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Bu da açıklayıcı faktör analizi için uygun olmayan veri setlerinde, KMO katsayısının 0.60'ın altında olduğuna ve dolayısıyla uygun sonuçlar alınamayacağına işaret ediyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
İstatistiksel analiz çalışmalarına genel anlamda bakıldığında, araştırmacıların bulguları üzerinden şu sonuca varabiliriz:
<!-- /wp:paragraph --><!-- wp:uagb/star-rating {"block_id":"287e21d0","rating":5,"size":21,"gap":0,"align":"center","color":"#cf2e2e","title":"\u003cstrong\u003eİyi bir analiz sonucunda KMO istatistiği en az 0.7 olmalı\u003c/strong\u003e","className":"uag-star-rating__wrapper uag-star-rating__layout-inline"} -->
İyi bir analiz sonucunda KMO istatistiği en az 0.7 olmalı
★★★★★
<!-- /wp:uagb/star-rating --><!-- wp:paragraph -->
Pratikte elde ettiğimiz veriler zaten belirli bir örneklem sayısına ve ilişkisel yapılara göre hazırlanıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Seçtiğimiz sorular mutlaka kendi aralarında ilişkili olacak biçimde seçiliyor ve örneklem hacmimiz de madde sayısının en az 5 ila 10 katı arasında değişiyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Soru yapılarımız ve örneklem hacmimiz üzerinde aldığımız tedbirler, KMO katsayısının sorunsuz çıkmasını sağlıyor.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Bu nedenle, uygulamada KMO katsayısının 0.70'in altında çıkması gibi bir problemle karşılaşılması, çok nadir bir durum.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Ayrıca ilk etapta düşük katsayılar elde edilse bile, düşük korelasyonlu maddeler açıklayıcı faktör analizi esnasında veriden atıldıkça, 0.70'in üzerinde bir değere (çok ekstrem bir durum olmadıkça) eninde sonunda ulaşıyoruz.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Bu yazımızda, araştırmacıların Google'da yoğun olarak arattığı KMO istatistiğine ilişkin birtakım bilgiler sunduk.
<!-- /wp:paragraph --><!-- wp:paragraph -->
Özellikle ölçek geliştirmek veya uygulamak isteyen anket araştırmacıları için yazımızın faydalı olmasını umuyoruz.
<!-- /wp:paragraph -->